169. Du choix éditorial au filtre algorithmique – Les intermédiaires de la communication en ligne ont un rapport très passif à l’information qu’ils véhiculent, si on les compare au rôle qu’endosse traditionnellement un directeur de publication ou un éditeur. L’impact de cette évolution sur le traitement des contenus manifestement illicites a été souligné. Là où l’intervention a priori de personnes humaines identifiées et personnellement responsables constituait une barrière dense, les intermédiaires numériques se contentent de réagir ponctuellement et après coup, lorsque les utilisateurs leur tirent la manche ou que les autorités leur en donnent l’ordre. Des milliers de contenus ostensiblement illégaux passent au travers des mailles de cet étrange filet.
Cette différence d’approche se prolonge lorsque l’intermédiaire numérique fait profession non seulement de véhiculer l’information, mais aussi de la mettre en forme et de la placer directement au contact de ses destinataires. Ce n’est pas le rôle d’un fournisseur d’accès, par exemple, ni celui d’un pur hébergeur, mais c’est bien celui d’un réseau social ou d’un moteur de recherche. Le rôle de l’éditeur classique consiste, à partir d’un espace de publication limité, à procéder à des choix. Prendre personnellement connaissance des contenus candidats à la publication lui permet non seulement d’écarter ceux qui dépassent nettement les limites de la liberté d’expression, et qui risqueraient de lui valoir une condamnation pénale, mais surtout de retenir une sélection, un ordre, une hiérarchie de l’information, produisant ainsi un discours conscient et assumé sur le monde.
Le réseau social ou le moteur de recherche dispose, quant à lui, d’un espace potentiellement infini pour afficher des publications ou des résultats. Aucun employé humain n’est chargé d’intervenir directement ni sur le périmètre ni sur l’ordre de ce qui s’affiche sur l’écran d’un utilisateur donné. Pour autant, ce n’est pas une matière brute qui est livrée à l’internaute. L’information n’est pas travaillée par l’homme, mais elle est filtrée, classée et positionnée par les machines. Cela est particulièrement évident s’agissant d’un moteur de recherche généraliste, où ces opérations ne sont pas le résultat d’un choix, mais une nécessité. Il n’existe pas d’ordre objectif ou naturel dans lequel les réponses à une requête donnée devraient s’afficher. Quelle est la page susceptible d’intéresser le plus un internaute interrogeant Google ou Qwant sur « Marcel Proust », « plus belle plage du monde » ou « conseils pour réussir ses études de droit » ? Il n’existe aucune réponse définitive et parfaite. En amont, un algorithme aura été conçu par ces sociétés, un ensemble d’opérations visant à manipuler des informations, une machine à pétrir la connaissance. C’est une boîte noire : un problème à résoudre y entre, une réponse en sort, et la qualité de cette réponse est soumise au jugement personnel de chaque utilisateur. De leur satisfaction dépend leur fidélité ; de leur fidélité dépendent les revenus publicitaires sur lesquels repose une large part du modèle économique de ces compagnies. Mais les moteurs de recherche ne sont pas les seuls concernés. Les réseaux sociaux n’ont théoriquement pas l’obligation d’y recourir. En effet, il existe pour eux une manière objective d’afficher l’information, par exemple en montrant à chaque utilisateur l’intégralité des contenus publiés par ses contacts, dans un ordre purement chronologique. Il y a un risque : plus ces réseaux gagnent en popularité, plus un individu donné aura « d’amis », et plus son fil d’actualités grossira, jusqu’à ce qu’il se noie dans un flux ininterrompu de publications, d’interactions et de commentaires. Dans cette masse d’informations, le risque est grand qu’une partie ne l’intéresse, ne l’amuse ni ne le stimule d’aucune façon. Il se connectera alors au réseau de plus en plus rarement, et finira par l’abandonner sans même s’en apercevoir. Le problème ne se pose plus s’il est possible de prédire quels contenus il aura plaisir à consulter, pour les lui proposer exclusivement ou en priorité. C’est le choix opéré de longue date par le réseau dominant, Facebook.
Les actualités qui s’affichent dans votre fil d’actualité sont sélectionnées en fonction de votre activité et de vos contacts sur Facebook. Vous pouvez voir ainsi davantage d’actualités susceptibles de vous intéresser, notamment celles des amis avec lesquels vous communiquez le plus. L’affichage d’une actualité dans votre fil d’actualité dépend notamment du nombre de commentaires et de mentions « J’aime » qu’elle reçoit, ainsi que de sa nature (par exemple, s’il s’agit d’une photo, d’une vidéo ou d’un nouveau statut) 1Extrait de la page « comment fonctionne le fil d’actualité ? » : http://www.facebook.com/help/327131014036297/..
Le réseau Twitter, après avoir longtemps retenu un système d’affichage exhaustif et purement chronologique des contenus, s’est finalement doté à son tour d’un algorithme de discrimination 2V. par ex. W. Oremus (trad. A. Bourguilleau), « Voici comment fonctionne l’algorithme de Twitter », article Slate.fr du 10 mars 2017..
170. Un pouvoir sans responsabilité ? – Ainsi, consulter un résultat de recherche ou un réseau social, ce n’est plus dialoguer avec l’intellect d’un directeur de publication, mais se présenter devant une machine, un distributeur automatique d’information « pertinente ». Cette évolution n’est pas sans conséquence juridique, comme le montre une affaire restée fameuse sous le nom de « Google Suggest ». Cette fonctionnalité du moteur de recherche orientait non pas les résultats de recherche, mais les questions qui lui étaient posées. Au fur et à mesure que la requête était saisie, le moteur formulait un certain nombre de propositions jugées statistiquement probables sur ce que serait la suite de la question. Du point de vue qui nous intéresse, le mécanisme est comparable à celui qui classe les résultats de la recherche. Dans les deux cas, il s’agit d’apporter à l’internaute une information jugée pertinente pour lui, en se fondant sur l’intérêt manifesté par tous ceux qui l’ont précédé dans la même voie. Le panurgisme de l’algorithme fait sa force, en indiquant à celui qui le consulte où se dirige la majorité, mais il est aussi sa faiblesse : lorsque les masses prennent une direction qui devrait l’alerter, il les suit sans guère hésiter. En l’espèce, un grand nombre d’internautes avait soumis des requêtes associant le nom d’une société et le terme « escroc ». Suggest en avait pris acte, et proposait à toute personne saisissant le nom de l’entreprise d’y accoler ce terme indubitablement injurieux. Le moteur de recherche avait été condamné par une cour d’appel, de même que son directeur de la publication, aussi sévèrement que si ce dernier avait dirigé un journal.
[…] le fait de diffuser auprès de l’internaute l’expression « lyonnaise de garantie, escroc » correspond à l’énonciation d’une pensée rendue possible uniquement par la mise en œuvre de la fonctionnalité en cause, qu’il est acquis aux débats que les suggestions proposées aux internautes procèdent des sociétés Google à partir d’une base de données qu’elles ont précisément constituée pour ce faire, lui appliquant des algorithmes de leur fabrication, que lee recours à ce procédé n’est que le moyen d’organiser et de présenter les pensées que la société Google met en circulation sur le réseau interne 3CA Paris, 14 décembre 2011, N° 11/15029, dans la version ramassée qu’en donne Cass. 1ère civ., 19 juin 2013, n° 12-17.591. Souligné par nous..
Cette décision a été censurée par la Cour de cassation.
[…] en statuant ainsi, quand la fonctionnalité aboutissant au rapprochement critiqué est le fruit d’un processus purement automatique dans son fonctionnement et aléatoire dans ses résultats, de sorte que l’affichage des « mots-clés » qui en résulte est exclusif de toute volonté de l’exploitant du moteur de recherche d’émettre les propos en cause ou de leur conférer une signification autonome au-delà de leur simple juxtaposition et de leur seule fonction d’aide à la recherche, la cour d’appel a violé [les articles 29 et 33 de la loi de 1881] 4Cass. 1ère civ., 19 juin 2013, n° 12-17.591 : JCP G, 2013, 907, note A. Lepage. Souligné par nous..
La cour d’appel soulignait le rôle essentiel du moteur de recherche dans la circulation et la mise en scène de l’information. Elle se situait sur le terrain du pouvoir procuré par l’algorithme et sur les conséquences de son fonctionnement. La Cour de cassation, à l’inverse, met en avant ses ressorts internes. En effet, les délits de presse considérés ne peuvent être commis que si un élément intentionnel est retenu. Certes, s’il n’a pas de volonté propre, un algorithme peut être le véhicule d’une intention de la part de ses concepteurs – techniquement, rien n’empêche de favoriser sciemment des requêtes de recherche injurieuses ou racistes, par exemple. Mais tel n’était pas le cas en l’espèce, puisqu’il était le miroir fidèle des questions antérieurement formulées par la majorité. Si la solution retenue par la Cour se comprend, en ce qu’elle est cohérente avec les exigences de la matière pénale, elle fait naître de difficiles questions. D’abord, comment s’assurer concrètement de la neutralité de l’algorithme par rapport au fond des messages qu’il manipule, puisque leur code est généralement inconnu ? Ensuite, quand bien même cet ensemble d’opérations informatiques serait intrinsèquement neutre, l’affaire Google Suggest rappelle que son fonctionnement produit parfois des effets néfastes pour l’harmonie sociale.
L’effet puissant de ces ensembles d’opérations mathématiques sur la manière dont les citoyens s’informent et communiquent incite à surmonter — sans l’ignorer — l’argument de l’automaticité pour mieux ouvrir certains débats.
Récemment, des critiques ont surgi dans deux directions précises : l’excès de personnalisation de l’information par les algorithmes (A) et leur insuffisante sensibilité à la véracité de l’information présentée (B).
A – La personnalisation des contenus
171. Le biais de confirmation – Un premier reproche actuellement adressé aux algorithmes de sélection et de présentation d’informations consiste à dire qu’ils opèrent une personnalisation excessive des contenus. Dans le fonctionnement décrit ci-dessus de Google Suggest, il a été supposé que les propositions formulées seraient les mêmes pour tous les internautes tapant le début d’une question adressée au moteur. En réalité, la plupart du temps, les algorithmes se fondent sur ce qu’ils savent de la personne précise qui les interroge pour lui répondre. Ils se servent pour cela des données personnelles accumulées sur son compte par le passé 5V.supra, n ° 50 et s.. Un haut responsable de Google France en proposait un exemple 6Exemple donné à la tribune par M. Francis Donnat, alors directeur des politiques publiques de Google France, lors d’une conférence du 7 décembre 2015 sur « Enjeux juridiques, économiques et sociaux du numérique » organisée par la Société de Législation Comparée.. S’il se contente de saisir dans le moteur de recherche de son entreprise une suite de caractères en apparence absconse, comme « C-362/14 », l’algorithme comprendra qu’il s’agit d’un numéro d’arrêt rendu par la Cour de justice de l’Union européenne, car cet utilisateur déterminé a l’habitude de consulter le site de la juridiction. La même requête formulée par une personne ayant d’autres centres d’intérêt conduira à des résultats différents. L’exemple est innocent, et met en scène la capacité — réelle — de ces techniques à faire économiser à leurs utilisateurs du temps et de l’énergie, en devançant leurs désirs et en se contentant d’indications fragmentaires pour fournir un service performant. Mais une illustration politiquement moins neutre en révèle les dangers. Selon un auteur américain, Eli Pariser, si une personne politiquement marquée à droite et une autre plutôt à gauche lancent une recherche Google sur les lettres « BP », « La première reçoit, en tête de page, des informations sur les possibilités d’investir dans la British Petroleum, la seconde sur la dernière marée noire qu’a causée la compagnie pétrolière britannique » 7F. Joignot, « Sur internet, l’invisible propagande des algorithmes », article lemonde.fr du 15 septembre 2016. L’exemple est tiré de E. Pariser, The filter bubble : how the new personalized web is changing what we read and how we think, Penguin books, 2012.. Il qualifie ce phénomène, qui consiste à regarder la réalité de manière différenciée au travers des algorithmes, de « bulle de filtres » 8Du nom de l’ouvrage précité The filter bubble.. Il poursuit sa démonstration en l’étendant à Facebook, où les automatismes chargés de trier les publications de l’ensemble de ses amis pour en extraire ce qu’il aura le plus de plaisir à lire ont peu à peu fait disparaître ceux de ses contacts dont il ne partageait pas les conceptions 9Ibid.. Sa tendance à moins ouvrir les liens qu’ils proposaient et à moins leur accorder de « j’aime » aurait été repérée et amplifiée par le réseau social. Il y a deux manières de voir cet exemple : soit l’algorithme s’est contenté de rendre visible un comportement préexistant visant à éviter l’inconfort intellectuel, soit il l’a amplifié.
Cette stratégie d’esquive des idées contrariant notre vision du monde n’est effectivement pas nouvelle dans son principe. Elle est connue en psychologie sous le nom de « biais de détermination », et Francis Bacon la décrivait très bien il y a près de quatre siècles.
The human understanding when it has once adopted an opinion (either as being the received opinion or as being agreeable to itself) draws all things else to support and agree with it. And though there be a greater number and weight of instances to be found on the other side, yet these it either neglects and despises, or else by some distinction sets aside and rejects, in order that by this great and pernicious predetermination the authority of its former conclusions may remain inviolate […] 10F. Bacon, The new organon, 1620, XLVI..
172. L’amplification du biais par les algorithmes – Une fois encore, les technologies numériques se contentent donc d’exacerber une difficulté très ancienne. Comme le relève M. Dominique Cardon, à propos du fil d’actualités de Facebook : « […] ce sont les utilisateurs qui, à travers les liens sur lesquels ils choisissent de cliquer, referment la bulle sur eux-mêmes. Les libéraux lisent des informations libérales et les conservateurs des informations conservatrices » 11D. Cardon, À quoi rêvent les algorithmes ? Nos vies à l’heure des big data, Seuil, 2015.. Pour lui, cela n’empêche pas la critique de ces technologies, mais la déplace.
C’est en effet le comportementalisme radical des nouvelles techniques de calcul qu’il faut questionner. Avec une insistance provocante, les concepteurs des algorithmes prédictifs ne cessent de dire qu’ils ne font que s’appuyer sur les comportements passés de l’internaute pour lui recommander des choses à faire […] Le comportementalisme radical joue ce rôle à la fois lucide et démoralisant de démontrer à des sujets qui pensaient s’être émancipés des déterminations que, en ce qu’ils pensent être des singularités inassignables, ils continuent à être prévisibles, petites souris mécaniques dans les griffes des calculateurs 12Ibid..
Les arguments des promoteurs des algorithmes de personnalisation ont une portée essentiellement pratique : il s’agit de rendre la navigation rapide, efficace, performante. L’utilisateur ne fait qu’emprunter des raccourcis à travers le maquis informationnel, et arrive sans attendre à destination. Eût-il passé des heures à se promener à travers les contenus, c’est là qu’il se serait arrêté pour finir : la machine le sait mieux que lui, car elle le connaît mieux qu’il se connaît lui-même. Alors, pourquoi perdre son temps ? En réalité, ce discours est sous-tendu par une véritable vision politique de ce qu’est l’acte de s’informer, et plus fondamentalement encore de ce qu’est l’être humain.
L’algorithme, pourtant, n’est pas infaillible, et M. Cardon en propose un exemple.
Latanya Sweeney, une chercheuse en informatique afro-américaine, a remarqué que, lorsqu’elle tapait son nom dans le moteur de recherche de Google, elle voyait apparaître la publicité « Latanya Sweeney arrested ? ». Cette publicité propose un service de consultation en ligne […] qui permet […] de savoir si les personnes ont un casier judiciaire. Or, le nom de ses collègues blancs n’était pas associé au même type de publicité […]. (L’algorithme) ne comporte pas de règle lui demandant de détecter les personnes noires et les personnes blanches. Il se contente de laisser faire les régularités statistiques qui font que les noms et prénoms des personnes noires sont statistiquement plus souvent liés à des recherches de casier judiciaire. Livré à lui-même, le calculateur s’appuie sur les comportements des autres internautes et contribue, « innocemment », si l’on ose dire, à la reproduction de la structure sociale, des inégalités et des discriminations 13D. Cardon, op. cit., p. 84..
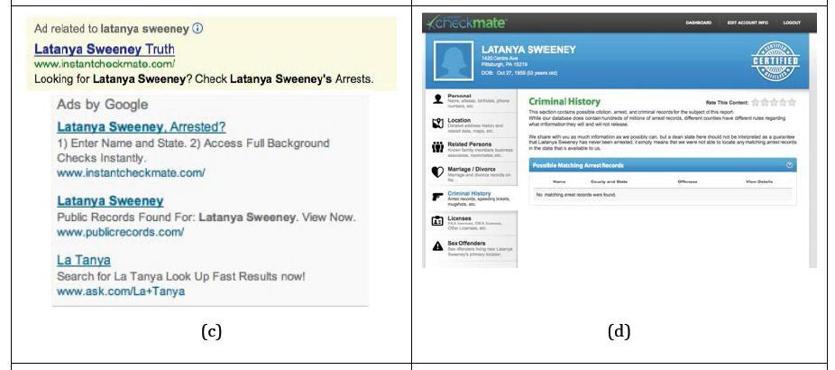
Les publicités que Mme Sweeney présente comme ayant été affichées pour une requête portant sur son nom (source : https://www.bostonglobe.com/business/2013/02/06/harvard-professor-spots-web-search-bias/PtOgSh1ivTZMfyEGj00X4I/story.html)
Il serait facile de qualifier cet exemple de pathologique, d’y voir un simple raté, et de l’écarter en conséquence d’un revers de la main.
Ce serait passer à côté de ce qu’il révèle de très profond dans le fonctionnement des algorithmes de personnalisation. Il est au contraire très riche d’enseignements, car il donne à voir, en le grossissant, un défaut d’approche habituellement plus discret. Lorsqu’il détermine quel maître il doit saisir, l’automatisme n’a pas la capacité de saisir l’individu ni les groupes auxquels il appartient dans toute leur complexité. Deux approches sont alors possibles, l’une déductive, l’autre inductive. L’approche déductive consiste à établir un « profil » de l’utilisateur qui comprendra par exemple certains centres d’intérêts majeurs, un historique de ses habitudes de consommation, des orientations politiques. Il en résulte au mieux une épure, au pire une caricature, dans tous les cas une extrême simplification du réel. L’autre approche est inductive, et repose sur la notion déjà évoquée de big data. Si des milliers d’individus ont en commun d’avoir acheté trois livres A, B, C et qu’un algorithme de recommandation se trouve face à un utilisateur n’ayant acheté qu’A et B, il va recommander C. Cette règle aura été construite à partir d’une pure série d’observations, sans qu’on ne cherche jamais à y accoler une tentative d’explication. C’est un monde de « corrélations sans causalité » qui se prépare, dont Mme Sweeney a été victime et contre lequel M. Cardon met en garde 14Ibid..
Notre société n’a pas attendu les algorithmes pour se fragmenter en sous-groupes qui communiquent trop peu. Mais les filtres numériques, qu’ils procèdent par portraits-robots ou par pures corrélations, risquent d’accentuer ces ruptures et de les rendre irréversibles. Des visions du monde qui se rencontraient peu ne se croiseront jamais. Chacun, dans sa vie en ligne, sera placé dans un cocon d’informations qui exacerberont sa vision du monde sans jamais heurter ses goûts. À un niveau individuel, l’individu sera perpétuellement ramené, par des mécanismes discrets et infatigables, à la position intellectuelle qui était la sienne par le passé. Les algorithmes dits « prédictifs » ne prévoient pas comment une personne peut évoluer, mais seulement comment elle s’apprête à réagir si elle reste strictement égale à elle-même sa vie durant.
Faut-il y voir une prise de conscience ? YouTube diffusait durant la campagne présidentielle française de 2017, une vidéo intitulée « Forgeons nos opinions. Découvrez d’autres opinions pour faire avancer le débat » 15Vidéo du 9 avril 2017 (https//youtu.be/gWsG-6vyqfo). Il n’est toutefois pas certain qu’il s’agisse d’une campagne contre le repli intellectuel engendré par la bulle filtrante : le propos essentiel est d’encourager les utilisateurs à s’abonner aux « chaînes » de certaines stars de la plateforme de vidéos en ligne, afin de s’exposer à la diversité d’opinions qu’ils sont supposés véhiculer.. L’initiative est louable, mais il faudrait aller un peu plus loin.
173. Révéler sans interdire – Personne n’a songé à forcer les lecteurs de Libération à souscrire un abonnement au Figaro, ou les admirateurs d’Adam Smith à ouvrir le Capital. S’il est toujours souhaitable que les citoyens s’exposent en permanence à différentes visions du monde, il n’est pas question de les y contraindre. Mais lorsqu’il s’abonne à un journal ou qu’il parcourt l’œuvre d’un auteur identifié, l’individu a certainement une conscience même confuse de ce qu’il a effectué un choix, au sein de l’univers des informations qui lui sont offertes. Chez le buraliste, ou sur les étals du libraire, les idées concurrentes s’étalent, à portée de main. Les ignorer, c’est prendre une décision. Une promenade dans un univers numérique « personnalisé » fait oublier jusqu’à l’existence d’alternatives, qui ne se présenteront même plus au regard. Les publications « adverses », dont il eût été profitable de voir passer tout de même le tire et un résumé, auront été éliminées à force de n’avoir jamais été ouvertes et manipulées longuement. À ce caractère souterrain de l’impact des algorithmes, s’ajoute la difficulté à vérifier s’ils ne sont pas tout simplement biaisés par leurs concepteurs, qui chercheraient non pas à enfermer l’individu pour toujours dans un concentré de lui-même, mais à influencer son jugement, petit à petit, dans le sens d’une opinion particulière. L’enjeu n’est donc pas d’interdire ces techniques de personnalisation, mais de rendre l’internaute conscient de ce que l’information qui lui est adressée est biaisée – au sens neutre de ce terme, car ce biais peut fort bien lui convenir. Afin de rendre le biais observable, deux directions complémentaires peuvent être explorées : en révéler les critères ; permettre qu’il soit contourné.
Une première direction consiste à mettre au jour les critères utilisés par les plateformes. Depuis la loi République numérique, ces acteurs ont l’obligation de procéder par eux-mêmes à la révélation des principaux facteurs influant sur leur sélection de l’information. Le Code de la consommation dispose en effet :
II. – Tout opérateur de plateforme en ligne est tenu de délivrer au consommateur une information loyale, claire et transparente sur :
1° Les conditions générales d’utilisation du service d’intermédiation qu’il propose et sur les modalités de référencement, de classement et de déréférencement des contenus, des biens ou des services auxquels ce service permet d’accéder ;
2° L’existence d’une relation contractuelle, d’un lien capitalistique ou d’une rémunération à son profit, dès lors qu’ils influencent le classement ou le référencement des contenus, des biens ou des services proposés ou mis en ligne (…) 16Art. L. 111-7 C. conso. dans sa rédaction issue de la loi n° 2016-1321 précitée..
Un décret, qui n’a pas encore été pris, doit préciser les conditions d’application de ce texte « en tenant compte de la nature de l’activité des opérateurs de plateforme en ligne ». Mais comment vérifier que les informations fournies par les professionnels sont justes et exhaustives, que rien n’est dissimulé ? Le contenu précis de l’algorithme, lorsqu’il est exploité par un acteur privé, est un secret de fabrication : il n’est pas révélé au public et ne peut pas l’être. Dès lors, pour connaître leur fonctionnement intime, il faut procéder par expériences méthodiques et nombreuses. C’est pourquoi le Conseil national du numérique préconise la création « d’agences de notation pour mesurer les niveaux de neutralité » des plateformes. Il s’agit de :
Développer des agences de notation de la neutralité pour révéler les pratiques des plateformes et éclairer les usagers et partenaires dans leurs choix. Les doter de moyens d’enquête et d’observation pour les mettre en mesure de développer des indicateurs efficaces. Ces agences pourraient prendre plusieurs formes : publiques, privées, associatives ou basées sur la multitude (crowd) et la société civile 17CNNum, rapport Neutralité des plateformes…, précité, recommandation 2, p. 11..
Un rapport du Conseil général de l’économie développe des propositions du même type : « Créer une plateforme collaborative scientifique, destinée à favoriser le développement d’outils logiciels et de méthodes de test d’algorithmes », mais aussi « Créer une cellule de contrôle spécialisée “bureau des technologies de contrôle de l’économie numérique”, pour l’ensemble des pouvoirs publics, implantée au sein de la DGCCRF » 18Conseil général de l’économie, Modalités de régulation des algorithmes de traitement des contenus, rapport de mai 2016, p. 41 et s.
Une deuxième direction, lorsque l’on cherche à rendre observables les biais dans la sélection d’information par les plateformes, est plus interventionniste. Elle oblige ces acteurs à proposer une information « non personnalisée ». Ainsi qu’il a déjà été exposé, tout réseau social est en mesure d’offrir à l’utilisateur une vue exhaustive et purement chronologique des publications opérées par ses contacts. Il devrait toujours être possible d’afficher cette vue. En revanche, un moteur de recherche n’a pas la possibilité de présenter des résultats « neutres », puisque toute sélection de sites opérée à partir d’une requête est une opération subjective 19Lorsqu’un réseau social comme Facebook propose des suggestions — vous venez de lire tel article A proposé par l’un de vos contacts, vous aimerez probablement aussi les articles B et C —, on ne sait pas si ces suggestions seraient faites de la même manière à tout internaute ayant lu A, ou si elles sont personnalisées. Si elles sont personnalisées, il devrait être possible d’en obtenir une version non personnalisée.. Mais le moteur de recherche Google ne présente pas les mêmes résultats à un internaute identifié et à un « inconnu » – qui n’a pas de compte Google, et dont ni l’adresse IP, ni les cookies, ni aucune « trace » numérique ne permet de le rattacher à des habitudes passées. Chacun devrait pouvoir demander à être traité « comme un inconnu ». Cela permettrait aux utilisateurs, sans les y contraindre, de procéder par comparaison entre les résultats filtrés et les résultats bruts 20Pour faciliter cette comparaison, Mme Amal Taleb, vice-présidente du CNNum, proposait que le réseau social ou moteur de recherche affiche simultanément au moins deux onglets de résultats, l’un « personnalisé » et l’autre non (intervention au colloque « Le droit des personnelles », Amiens, 7 novembre 2016).. Ils verraient à l’œuvre les forces qui modèlent l’information dont ils sont consommateurs au quotidien. Libres à eux, ensuite, de retourner vers le confort d’un monde entièrement conçu à partir de leurs désirs, ou de dégonfler un peu la « bulle » de subjectivité qui les entoure, faute de pouvoir jamais la percer.
B – La véracité des contenus
174. « Fake news » et manipulations de masse – Un peu plus d’un mois avant son départ du pouvoir, M. Barack Obama a clairement affirmé que la Russie avait utilisé Internet pour peser sur le cours de l’élection présidentielle américaine. D’une part, des attaques informatiques auraient permis de dérober puis de laisser filtrer des informations sensibles concernant le Parti démocrate, et en particulier à sa candidate Hillary Clinton 21V. par ex. E. Dvinina, « États-Unis : quelle riposte aux piratages russes ? », article lemonde.fr du 19 décembre 2016.. D’autre part, de fausses rumeurs, des informations mensongères patiemment diffusées des mois durant, auraient contribué à modeler lentement l’opinion publique américaine : les désormais célèbres fake news 22Pour une étude universitaire de l’impact de ces fake news sur l’élection présidentielle américaine : H. Allcott et M. Gentzkow, « Social media and fake news in the 2016 election », Journal of Economic Perspectives, Volume 31, Number 2, Spring 2017, p.211–236, consultable sur le site de l’Université de Standford : https://web.stanford.edu/~gentzkow/research/fakenews.pdf.. Une responsable du média russe Sputnik dévoile ainsi sa vision très particulière du journalisme : « There are many different truths », « There has to be a pluralism of truth » 23A. Higgins, « It’s France’s turn to worry about election meddling by russia », article Nytimes.com du 17 avril 2017.. Cette dangereuse rhétorique des vérités multiples devait, croyait-on, rester cantonnée à quelques milieux interlopes. Mais l’élection de M. Donald Trump à la présidence des USA l’a convoquée directement dans les discours officiels de la plus grande démocratie du monde. Ainsi, le porte-parole de la Maison-Blanche avait affirmé, contre toute évidence, que l’investiture avait mobilisé une foule sans aucun précédent historique. Interrogée sur ce mensonge, la conseillère Kellyanne Conway proposa une réponse qui restera dans les mémoires : « [the press secretary] gave alternative facts » 24Interview du 22 janvier 2017, sur laquelle V. par ex. A. Blake, « Kellyanne Conway says Donald Trump’s team has « alternative facts »… », article thewashingtonpost.com du 22 janvier 2017.. Par la suite, le président retourna l’expression fake news, dont on aura compris qu’elle avait été forgée pour dénoncer les informations frelatées issues de sources douteuses, contre les médias traditionnels, affublant par exemple le vénérable New York Times de ce qualificatif. Le journal se défendit en diffusant un spot dont le mot d’ordre était : « The truth is hard to find. The truth is hard to know. The truth is more important than ever ».
Extrait d'une émission de la chaîne NBC du 22 janvier 2017.
Ainsi M. Trump a-t-il légitimé un discours consistant à nier toute forme de hiérarchie entre les grands quotidiens d’investigation et les sites complotistes, entre les reporters professionnels et les blogueurs militants. Les citoyens sont encouragés à rechercher en ligne « les » vérités qui leur seraient cachées par les médias traditionnels. Les supports à privilégier seraient ceux qui n’ont ni la compétence, ni les moyens humains et financiers, ni même et surtout l’objectif de rechercher la vérité. Faits et opinions sont confondus ; la rotondité de la Terre devient un simple point de vue, et la science une croyance 25Sur ce dernier point : D. Larousserie, P. Barthélémy et C. Lesnes, « Après l’élection de Trump, la science entre en résistance », article lemonde.fr du 17 avril 2017.. Internet, dont les utopistes imaginaient qu’il rendrait le savoir accessible à tous, abolit les frontières du vrai et du faux, fond certitudes et rumeurs dans son chaudron brûlant. Le risque de régression est réel. Des réponses juridiques peuvent-elles être envisagées ?
175. Le délit de diffusion de fausses nouvelles – À rebours des tendances qui viennent d’être exposées, le droit français distingue les opinions, qui sont libres et la prise de position sur la réalité d’un fait, qui est encadrée. Affirmer quelque chose d’objectivement faux ne suffit pas, bien heureusement, à encourir les foudres du droit pénal. Des conditions supplémentaires sont exigées pour que soit constitué l’un des délits dits « de fausses nouvelles » 26Sur l’ensemble de cette question, V. N. Deffains et J.-B. Thierry, « Fausses nouvelles » in Rép. pén. Dalloz, juillet 2015.. Le plus important d’entre eux, de par la généralité de son champ d’application, est prévu par la loi de 1881 sur la liberté de la presse :
La publication, la diffusion ou la reproduction, par quelque moyen que ce soit, de nouvelles fausses, de pièces fabriquées, falsifiées ou mensongèrement attribuées à des tiers lorsque, faite de mauvaise foi, elle aura troublé la paix publique, ou aura été susceptible de la troubler, sera punie d’une amende de 45 000 euros 27Article 27 de la loi de 1881 précitée. Le deuxième alinéa ajoute : « Les mêmes faits seront punis de 135 000 euros d’amende, lorsque la publication, la diffusion ou la reproduction faite de mauvaise foi sera de nature à ébranler la discipline ou le moral des armées ou à entraver l’effort de guerre de la Nation »..
D’autres incriminations sont sectorielles, tel ce texte Code électoral.
Ceux qui, à l’aide de fausses nouvelles, bruits calomnieux ou autres manœuvres frauduleuses, auront surpris ou détourné des suffrages, déterminé un ou plusieurs électeurs à s’abstenir de voter, seront punis d’un emprisonnement d’un an et d’une amende de 15 000 euros 28Article L 97 du Code électoral. Sur les autres délits de fausses nouvelles : N. Deffains et J.-B. Thierry, art. préc., n° 5 s..
Dans tous les cas, la « nouvelle » doit s’entendre comme une « annonce d’un événement arrivé récemment, faite à quelqu’un qui n’en a pas encore connaissance » 29CA Versailles, 4 février 1998, approuvée par Cass. crim., 13 avril 1999, n° 98-83.798.. Sont donc potentiellement concernées les pseudo-révélations mensongères portant sur une actualité, qui sont nombreuses chaque jour en ligne, mais pas « les commentaires, aussi choquants soient-ils, portant sur des faits antérieurement révélés » 30Même arrêt. De tels commentaires peuvent néanmoins tomber sous le coup d’une autre infraction, par exemple, au cas d’espèce, la diffamation..
Les autres conditions d’application sont exigeantes. Les textes requièrent la démonstration d’un important trouble social : la paix publique doit avoir été touchée ou avoir été près de l’être dans un cas, et des suffrages doivent avoir été perdus ou détournés dans l’autre. Surtout, une véritable intention de nuire doit avoir animé celui qui a publié ou propagé la nouvelle. Le premier texte la réclame explicitement, qui vise la « mauvaise foi » ; le second, implicitement, qui fait allusion à des suffrages « surpris ou détournés », ce qui ne peut être le résultat que d’une manœuvre volontaire.
176. L’absence d’illicéité manifeste de l’acte de relais – Dès lors, il sera très difficile d’agir contre l’écrasante majorité des internautes, qui se seront contentés de relayer une fausse nouvelle à laquelle ils ont très bien pu croire. Nous avions vu que l’infraction de diffamation était constituée par la simple reproduction de propos attentatoires à l’honneur ou à la réputation : c’était ensuite à l’internaute d’exciper de sa bonne foi 31V.supra, n°142.. Ici, c’est à l’accusation de démontrer la mauvaise foi. L’obstacle n’est certes pas insurmontable, mais comment l’infraction sera-t-elle utilisée, de fait ? Les autorités, avec le concours du réseau social qui a servi à la propager le cas échéant, tâcheront de remonter à l’origine des rumeurs, à ceux qui les ont fabriquées parce qu’ils y ont intérêt. Ce seront les instigateurs qui seront punis, et un petit nombre de relais du premier cercle dont on aura pu démontrer qu’ils partageaient leurs mauvais desseins. En revanche, l’écrasante masse des internautes aura souvent eu le seul tort d’être naïve ou crédule. Le résultat est que le partage d’une fausse nouvelle présentera rarement un caractère manifestement illicite. Or, nous avons vu que l’illicéité devait crever les yeux pour qu’un intermédiaire numérique puisse se voir reprocher d’être resté inerte après un signalement par un utilisateur 32V.supra, n °163..
Telle est en tout cas la situation du droit positif. Une proposition de loi avait envisagé de faire évoluer très nettement la situation des plateformes 33Proposition de loi n° 470 visant à définir et sanctionner les fausses nouvelles ou « fake news », déposée à la Présidence du Sénat par Mme Nathalie Goulet.. Plusieurs nouveaux textes devaient place au sein du Code pénal, parmi lesquels celui-ci :
Art. 226-12-2. – Doit notamment être considéré de mauvaise foi, l’éditeur, le diffuseur, le reproducteur, le moteur de recherche ou le réseau social ayant maintenu à la disposition du public des nouvelles fausses non accompagnées des réserves nécessaires pendant plus de trois jours à compter de la réception du signalement par un tiers de leur caractère faux.
« L’éditeur, le diffuseur, le reproducteur, le moteur de recherche ou le réseau social à qui a été signalé le caractère faux des nouvelles peut néanmoins démontrer sa bonne foi en rapportant la preuve de l’accomplissement de démarches suffisantes et proportionnelles aux moyens dont il dispose afin de vérifier le contenu et l’origine de la publication mise à disposition.
Un seul signalement, réalisé par n’importe quel internaute, devait donc déclencher une enquête de la part d’un moteur de recherche ou réseau social. Le deuxième alinéa précisait cependant que les démarches devraient être « proportionnelles aux moyens dont il dispose ». Il est vrai que les ressources financières et humaines nécessaires pour procéder à des investigations complètes sur des milliers d’histoires douteuses sont potentiellement considérables. Sans ce deuxième alinéa, impossible d’imaginer un réseau social libre, décentralisé et à but non lucratif comme Mastodon 34Ce réseau est mis en œuvre notamment par des particuliers ou des associations, chacun utilisant son propre serveur.. Toutefois, la démarche « proportionnelle » semble difficilement compatible avec le principe de légalité des délits et des peines, tant il est difficile de déterminer a priori, pour un acteur donné, quel est le niveau de diligence attendu de sa part au regard de ses ressources. Laissons de côté cette objection, et raisonnons à partir de l’exemple des géants Facebook et Google, qu’on supposera dotés de moyens presque illimités. Même dans ce cas, le dispositif envisagé ne va pas sans susciter certaines réserves.
Cette proposition de loi semble devoir rester lettre morte. En revanche une proposition de loi relative à la lutte contre les fausses informations est débattue au moment où nous écrivons ces lignes, qui semble avoir de plus grandes chances d’être adoptée 35Proposition de loi n° 799 enregistrée le 21 mars 2018, relative à la lutte contre les fausses informations..
177. Facebook et Google, journalistes d’investigation ? – Le problème fondamental, s’agissant de ces fausses nouvelles, c’est que l’on attend des plateformes qu’elles pratiquent un métier qui n’est pas le leur. C’est une chose d’être chargé du retrait de contenus manifestement illicites, comme une négation de l’existence de la Shoah, ou l’appel à des violences contre un groupe d’individus caractérisé par son orientation sexuelle. C’en est une autre de procéder à des enquêtes pour démêler les actualités véritables des fake news. Dans le premier cas, il suffit de prendre connaissance de la publication pour connaître son devoir, qui est de la faire disparaître. Dans le second, il faudra mener des investigations, interroger des sources, procéder à des recoupements et des vérifications.
Nous rencontrerons d’autres exemples de cette tendance : celle qui voudrait traiter les nouveaux intermédiaires de l’économie numérique de la même façon que les acteurs anciens qu’elles ont partiellement évincés. Une plateforme de financement participatif permet aux internautes de se prêter de l’argent, sur la foi d’une description assez sommaire d’un projet industriel, artistique ou caritatif ? Il est tentant d’exiger de la plateforme qu’elle opère elle-même une sélection des projets les plus sérieux et qu’elle assume une responsabilité personnelle en cas d’échec, ce qui revient à terme à en faire… une banque, et à empêcher la multitude d’entrer en contact direct avec la multitude, ce qui était l’objectif initial. De la même façon, les réseaux sociaux ont permis aux utilisateurs de se retrouver en face les uns des autres par millions, l’intermédiaire se faisant le plus neutre et le plus discret possible. La tentation est grande de le ramener petit à petit vers un rôle de rédaction en chef, en exigeant de lui qu’il vérifie le contenu des discussions et qu’il distribue des mauvais points, le cas échéant. Il se voulait translucide, le voilà ramené vers la densité et la substance. Mais il ne faudrait pas oublier que sa déresponsabilisation n’est pas — totalement — artificielle : elle est une conséquence d’une modification véritable de son rôle. Le véritable rédacteur en chef assume professionnellement et juridiquement les publications d’une équipe délimitée, qu’il connaît. On demande ici aux intermédiaires numériques d’assurer le contrôle intellectuel d’une foule bigarrée et chaotique d’inconnus. Il serait sage de ne pas légiférer avant d’avoir pris le temps d’une réflexion sérieuse et construite sur les conséquences d’un tel modèle. Cela tombe bien : sans y être contraints — si ce n’est par la pression de l’opinion publique -, certains acteurs ont pris des initiatives qu’il sera bon d’observer avant d’agir.
178. Des initiatives récentes – Ne disposant pas en interne de toutes les forces nécessaires à la lutte contre la désinformation Google et Facebook ont, chacun à sa manière, décidé de faire appel à des forces extérieures.
L’approche récemment retenue par Google semble reposer sur le crowdsourcing, c’est-à-dire sur la sagesse du nombre. L’idée est de s’adresser à sa multitude de visiteurs pour signaler les contenus faux. Plutôt que de les retirer — ce qui impliquerait, pour l’entreprise, de procéder au préalable elle-même à une vérification complète de la véracité de l’information — elle dégradera progressivement la position des résultats de recherche ainsi dénoncés 36A. Grondin, « Google s’en remet aux internautes pour évacuer les “fake news” des recherches », articles leschos.fr du 26 avril 2017.. C’est sur ce système que Wikipédia compte depuis longtemps pour éviter que les articles de l’encyclopédie ne se trouvent remplis de mensonges. L’un des cofondateurs du site vient d’ailleurs d’annoncer le lancement d’un nouveau média en ligne visant à « réparer » l’information, et basé lui aussi sur le crowdsourcing 37W. Mérancourt, « Avec WikiTribune, un cofondateur de Wikipédia s’attaque aux “fake news” », article letemps.ch du 28 avril 2017..
Facebook, quant à lui, a décidé de sous-traiter les tâches de vérification à de grands médias traditionnels, dans le cadre d’un Journalism Project 38G. Pépin, « “Fake news” : Facebook va rémunérer des éditeurs français et fait sa publicité dans la presse », article nextimpact.com du 26 avril 2017.. Pour la France, les noms du Monde, de l’école de journalisme de Sciences Po, de l’Express, de France info, de Libération, de 20 Minutes et de BFMTV sont ainsi cités. La rémunération qui leur sera versée est en cours de négociation. Les contenus faux verront leur visibilité dégradée ou seront assortis d’un avertissement au lecteur : « Si deux médias partenaires établissent que le contenu signalé est faux et proposent un lien qui en atteste, alors ce contenu apparaîtra aux utilisateurs avec un drapeau mentionnant que deux “fact-checkers” remettent en cause la véracité de cette information. Quand un utilisateur voudra partager ce contenu, une fenêtre s’ouvrira pour l’alerter » 39A. Delcambre, « Huit médias français s’allient à Facebook contre les “fake news” », article lemonde.fr du 06 février 2017.. De plus, la publication ainsi marquée ne pourra pas servir de support à une exploitation publicitaire.
Si ces initiatives peuvent sembler louables, le risque d’une police privée des publications doit à nouveau être souligné, comme chaque fois qu’il est demandé aux plateformes d’agir sur des contenus qui ne sont ni manifestement illicites, ni objets d’une demande judiciaire de retrait 40V. déjàsupra, n° 107 et n°163. En ce sens, L. Lessig : « Ce que Facebook est en train de développer, un système très sophistiqué d’identifier et d’isoler les fake news, c’est effrayant. L’idée qu’une entité privée puisse se livrer à ce genre de censure est toujours inquiétante » (M. Untersinger, « Lawrence Lessig : “Le problème de la démocratie actuellement c’est qu’elle n’est pas représentative” », article lemonde.fr du 23 avril 2017).. Ce qui rassure, dans le projet actuel de Facebook, c’est qu’il repose sur un partenariat avec de véritables professionnels reconnus de l’information. Mais rien n’empêche cette entreprise de décider, plus tard, d’internaliser entièrement cette compétence, ce qui rendrait probablement son fonctionnement très opaque. Quant aux systèmes reposant sur la foule, comme celui de Google ou de Wikipédia, ils ne sont jamais à l’abri de manipulations à grande échelle, organisées par un acteur hostile. Pour se protéger contre la désinformation, le citoyen doit avant tout exercer son esprit critique, savoir croiser et hiérarchiser les sources, toutes choses qui s’enseignent mieux qu’elles ne se décrètent.
Concluons ces développements consacrés à la communication électronique.